

What is Machine Learning Classification?
First, let’s talk about machine learning classification.
Machine learning can be broadly divided into supervised learning, unsupervised learning, and reinforcement learning, depending on the type of data and circumstances. Among them, classification is a method that belongs to ” supervised learning “.
Therefore, I will first explain machine learning and supervised learning, and then I will explain “classification”.
What is machine learning
First of all, I will explain the outline of machine learning for those who do not know what machine learning is in the first place.
Machine learning is an AI technology that allows computers to discover patterns and rules from a large amount of data and use them in various ways for classification and prediction.
In general, image recognition algorithms trained on large amounts of image data and natural language processing algorithms trained on large amounts of text are in circulation, and the use of machine learning is progressing in various aspects of society. I’m in.
What is supervised learning
From here on, I will explain “ supervised learning ” to which the classification belongs.
Supervised learning is a method in which a computer is taught data that will be the correct answer in advance, and then judges whether it is correct or not when new data is given.
Supervised learning uses teacher data as known information for learning, and constructs regression models and classification models that can deal with unknown information.
For example, let’s build a model by training a computer with a large number of photos pre-labeled as “dogs” and “cats” (teaching data).
Given an unlabeled photo, the model will output the label attached to the trained image with the closest features to that image.
And this model will be able to detect that the given image is “dog” or “cat”.
Regression and classification belong to supervised learning, and neural network deep learning is a development of this ” supervised learning “.
What is classification
Classification in machine learning literally means “classifying various things”.
Specifically, if you have a picture of two animals, such as a dog and a cat, give each a discrete value such as 0 or 1. Then, if there is a newly loaded photo, it is sorted according to which value, 0 or 1, is closer.*Discrete value: A value that is not continuous, expressed as an integer such as 0 or 1, and has no intermediate value such as 0.5
Four typical machine learning classification algorithms
Algorithms are important when thinking about classification in machine learning. I will explain which algorithm to use later, but I would like to give a brief explanation of each algorithm here.
Here are the four most popular machine learning classification algorithms:
- decision tree
- logistic regression
- SVM (Support Vector Machine)
- Naive Bayes
I will explain each.
decision tree
A decision tree is a tree structure that can be divided into groups by conditional branching, and is a general term for regression trees that can be used for regression and classification trees that can be used for classification.
A decision tree is like the tree-shaped graph below and is used in risk management and other decisions.
Created by AINOW editorial department
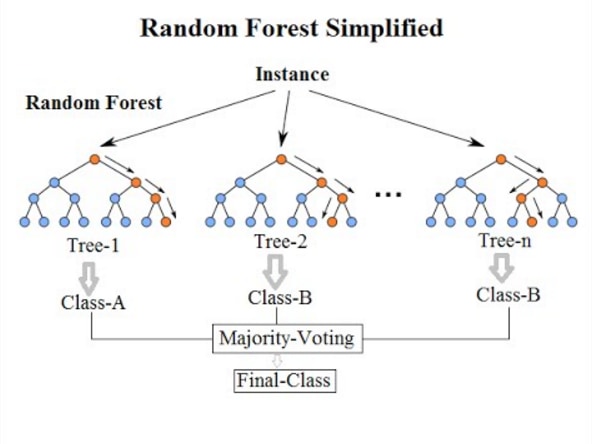
There is also a development called random forest that uses multiple decision trees to calculate the average and majority vote.
Random forest is a method that collects and analyzes multiple decision trees with different learning ranges, so it is possible to produce better analysis results than a single decision tree.
logistic regression
Logistic regression is an adaptation of the technique known as linear regression, and although regression is in the name, it is actually a technique used for classification problems.
Basically, it is used to classify “whether or not a certain thing happens”.
This model is simply a method that allows us to solve the classification problem by applying a logistic function (also known as a sigmoid function) to the linear polynomial used in linear regression.
Therefore, it is one of the simplest models for classification problems.
Support Vector Machine (SVM)
A support vector machine (SVM) is an algorithm that divides data by boundaries. It can be used for both regression and classification, but is primarily used for classification.
A support vector is “the data closest to the straight line that divides the data”. It uses a concept called “margin maximization” to find the correct classification criteria.
SVM has advantages such as good identification accuracy even if the dimension of data increases and a small number of trials, and is applied in the fields of stock price prediction and outlier detection.
Naive Bayes
Naive Bayes is an algorithm that uses Bayes’ theorem. Bayes’ theorem is a theorem that can be used to find the probability of a cause from the probability of a certain event, and is frequently used as the basis of statistics.
Naive Bayes has a low computational complexity and high processing speed, so it can handle large-scale data, but it has the problem of slightly low accuracy.
It calculates the probability of being classified into each class and outputs the class with the highest probability as a result, so it is used for text classification tasks such as spam filters.
Benefits of Machine Learning Classification
The advantage of classification is that it can be categorized. For example, I would like to consider the classification of dogs and cats that was mentioned earlier.
In supervised learning, you first enter the answer together, such as this picture is a dog, this picture is a cat, and so on. Then, when a new photo is read, it distinguishes between dogs and cats.
Classifying these categories into two is called binary classification, and more than that is called multi-class classification.
Dividing into these categories is one of the benefits of classification and one of the things machine learning is good at.
Disadvantages of Machine Learning Classification
In the previous section, I explained the advantages of classification, but this time I will explain the disadvantages of classification.
The disadvantage of classification is that “prediction of continuous values such as numerical prediction is not possible”. This is because the classification is good at classifying as the name suggests. Predicting continuous numerical values is the field of regression.
How to do classification in Python?
How can I do classification with Python, which is often used for machine learning?
Python has a Scikit-learn library. The Scikit-learn library comes with a sample dataset, so even beginners can start right away.
The Scikit-learn library can also perform classification and regression, so if you are interested, it would be a good idea to start.
3 Cheat Sheets to Determine Algorithms
When learning and utilizing classification, you may sometimes wonder, “What kind of algorithm should I use for this data?” In such a case, we recommend a “cheat sheet that can determine the algorithm”.
Use the three cheat sheets below to find the best algorithm just by answering the questions.
Scikit-learn
This is the official cheat sheet for Scikit-learn. All notations are in English, but since they are distributed by the official, they are highly reliable. The feature is that it is colored colorfully.
Scikit-learn
SAS Institute Japan
It is the Japanese subsidiary of the SAS Institute, which makes statistical analysis software headquartered in the United States. Japanese cheat sheet is open to the public. It is characterized by being divided into supervised and nonsupervised classes.
SAS Institute Japan
Machine Learning Algorithms Cheat Sheet – Azure Machine Learning
This is a cheat sheet published by Microsoft. It is characterized by being divided into detailed categories. Affinity will be high for those who use Microsoft’s cloud service Microsoft Azure.
A representative evaluation index for classification in machine learning
Let’s raise the level a little from here. In this chapter, we will look at the confirmation numbers that evaluate how well each algorithm produces results.
Accuracy
The accuracy rate is a numerical value that shows how many correct predictions are made after learning. In other words, it represents how many of the prediction results were correct.
Precision
Precision is the percentage of correct answers out of those predicted as correct answers by learning. In other words, it represents how many of the correct prediction results were correct.
Recall rate
Recall is the number of predictions that were correct out of the ones that were really correct. In other words, out of the correct data, it represents the prediction result judged to be correct.
Content to learn about machine learning classification
There are many ways to learn machine learning. In this chapter, we present three pieces of content that you can learn about machine learning classification.
technical book
The first is the method of “learning from technical books”. The content of technical books is reliable because the contents are properly proofread by each publisher.
Furthermore, if you want to learn more about classification, we recommend reading books written by experts, such as “ Illustrated Ready-to-Use Machine Learning & Deep Learning Mechanisms and Techniques All in One Textbook ”.
In addition, there are specialized books written by experts, so it is recommended if you want to learn more about classification.
learning site
The second is the method of “learning on the learning site”. Depending on the learning site, there are mechanisms to increase understanding, such as video content and the ability to ask questions to engineers.
There are various forms, from free to paid. For example, paiza and Udemy have content to learn more about machine learning.
school
The third is “learning at school”.
The school is characterized by being able to learn and ask questions from engineers who are active on the front lines. There are also “ AI job boyfriends ” that are easy to learn even for inexperienced and beginners .
There are many other ways to learn, such as lectures, universities, and vocational schools. Find a learning method that suits you and learn machine learning.
Summary
How was that. In this article, we have covered everything from the classification of machine learning to related information.
It is recommended to learn machine learning classification together with regression. It is good to learn while checking the difference between classification and regression.

{kind=link}