Do you know a machine learning model called “GPT-3”?
GPT-3 is a model for natural language processing. It has become a big topic when it behaves like a human being, mainly on SNS.
GPT-3 is arguably the hottest machine learning model in 2020. GPT-3 will continue to be a focus of attention in the future, but I think there are many people who do not know much about it.
Therefore, in this article, we will introduce “What is amazing about GPT-3”, including historical trends.
Table of Contents
- What is GPT-3
- Where did GPT-3 evolve from GPT-2
- Increased model size
- Diversification of data input
- GPT-3 performance experiment
- in conclusion
What is GPT-3

GPT-3 is a language model developed by a research institute called Open-AI.
“3” means the version name, and the GPT series developed by Open-AI in the past are GPT and GPT-2, and GPT-3 is the third developed language model.
The performance of the model has improved dramatically with each version. In response, GPT-3 has gradually evolved to behave like a human.
Not only the current GPT-3, but also the previous model GPT-2 attracted a lot of attention when it was released.
This is because Open-AI initially expressed concern that it could be used for fake news generation, etc., and released only a small model as “a model that is too dangerous” (currently, the full model is released).
However, due to the risk of being abused, the GPT-2 and GPT-3 models have not been published and are currently available only through the API. Also, in order to ensure the safety of the output results when using the API, the following alerts are issued for dangerous output.

Structurally, GPT-3 is almost identical to GPT-2. The architecture called Transformer has 96 layers, and it is a language model trained using large-scale data.
In this article, I will omit the explanation of the structure of those models and mainly focus on the comparison of the past series of GPT.
▶You can read more about Transformer in this article>>
Where did GPT-3 evolve from GPT-2
The GPT-3 has two major improvements compared to its predecessor, the GPT-2.
- Dramatically increased model size
- Diversification of data input formats
We will introduce each of these two features.
Increased model size
The GPT-2 paper also mentioned that the larger the model size (= number of parameters that can be learned), the better the performance. The following is a quote from the GPT-2 paper.
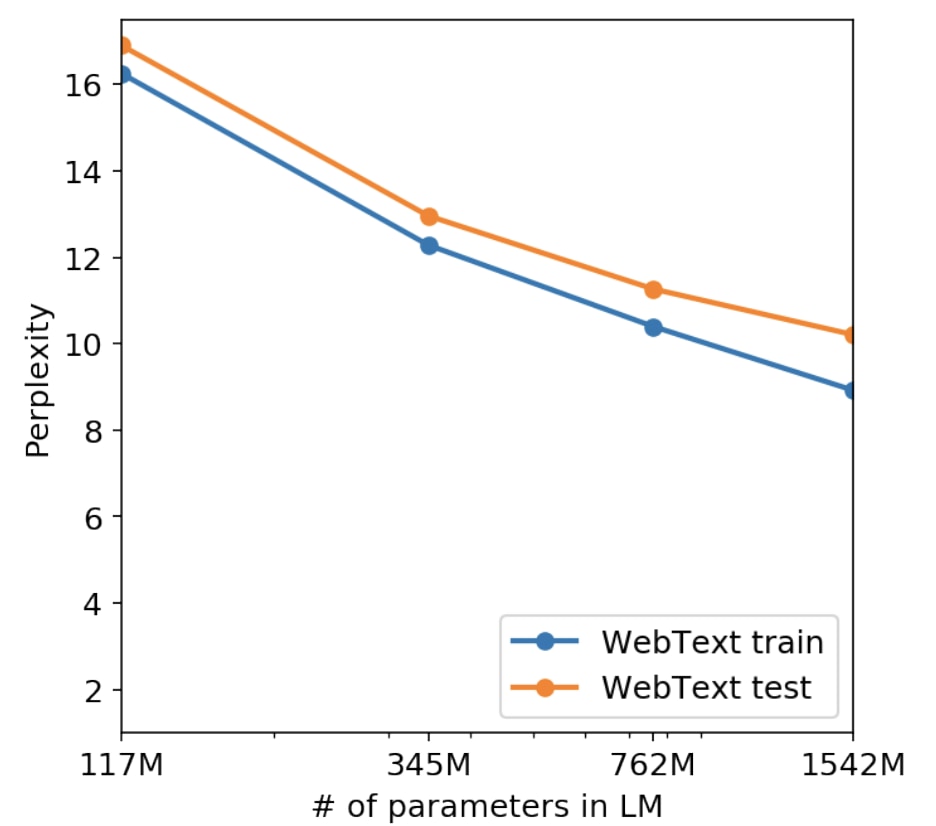
The horizontal axis is the size of the model, and the vertical axis is the performance. A lower performance value means a better metric.
According to this figure, the larger the model size, the better the performance. GPT-3 does this straightforwardly.
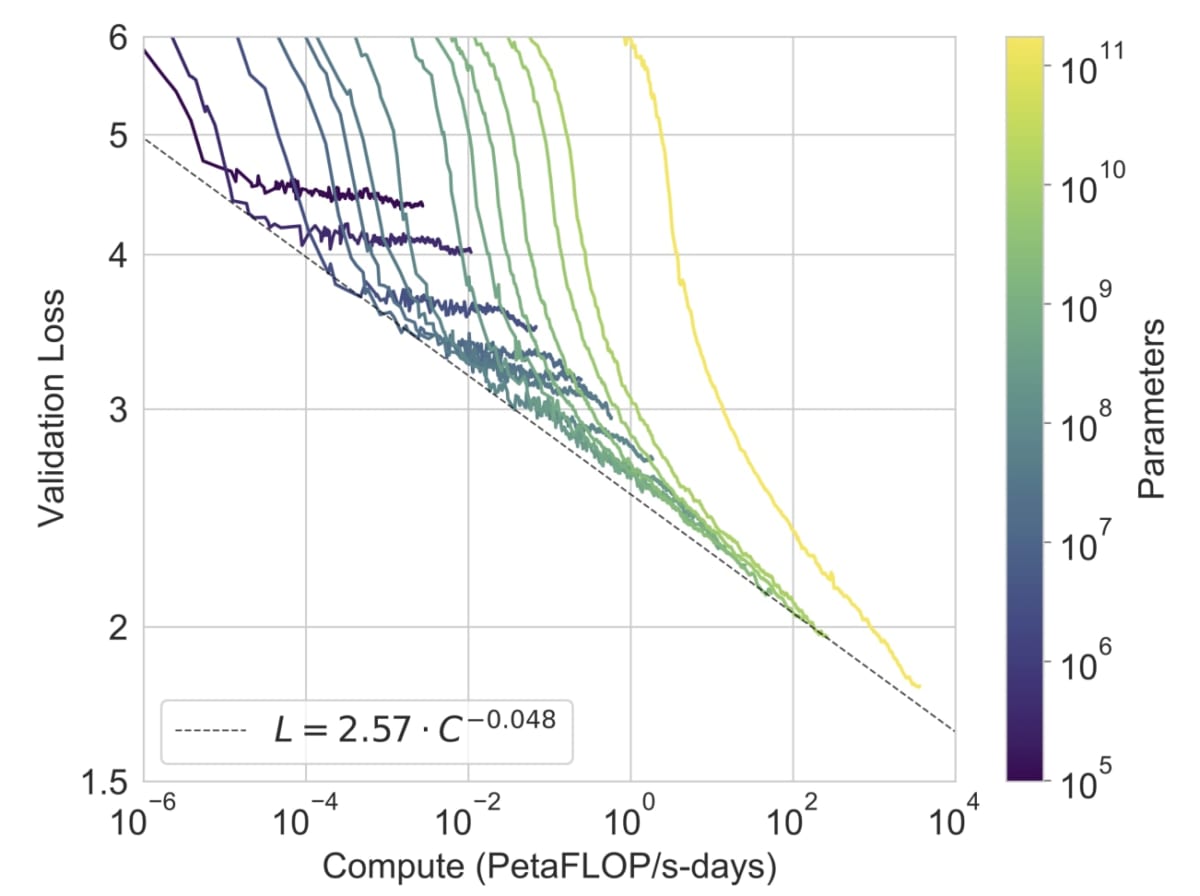
This figure plots how much the performance improves for each model size. The lower the line, the better the result.
GPT-3 is the yellow line on the far right. It turns out that it has the best performance among all models, and considering that the model size equivalent to GPT-2 is the fifth line from the right, the accuracy is considerably improved.
Here, focusing on the number of trained parameters, GPT-2 has 1.5B and GPT-3 has 175B, which is a difference of two orders of magnitude. This means that the number of parameters to train has increased by two orders of magnitude.
In the paper, this is expressed as a power law with the amount of computation (= amount of computation required for training), and according to this rule, the larger the model, the better the performance.
This performance scaling law will be a milestone for future natural language processing models. It is speculated that OpenAI is developing the next super-large model for performance update.
But there is a serious problem here. The amount of computation increases exponentially as the model size increases. In addition, the learning data has also increased significantly from “GPT-2: 40GB → GPT-3: 570GB”.
Due to this extremely large amount of computation, one theory is that training GPT-3 costs 4.6 million dollars. I’m here.
Diversification of data input
GPT-2 and GPT-3 generate output by having the model predict the continuation of a particular phrase. For example, given the following input:

In the example above, the first line asks, “Please translate from English to French, please,” and the second line asks, “What is “cheese” in French?”
It performs the translation by generating a natural continuation after the “=>”. In other words, the answer can be extracted from a general language model without task-specific training, and that is the great thing about GPT.
Another feature of GPT-3 is the increased diversity of data formats input to this model.
GPT-3 introduces a technique called In-context learning, which allows a more flexible input format by concatenating several examples into the input sequence.
In addition, in-context learning has significantly improved accuracy.
GPT-2 used only the Zero-shot format, but GPT-3 uses three input formats: Zero-shot, One-shot, and Few-shot.
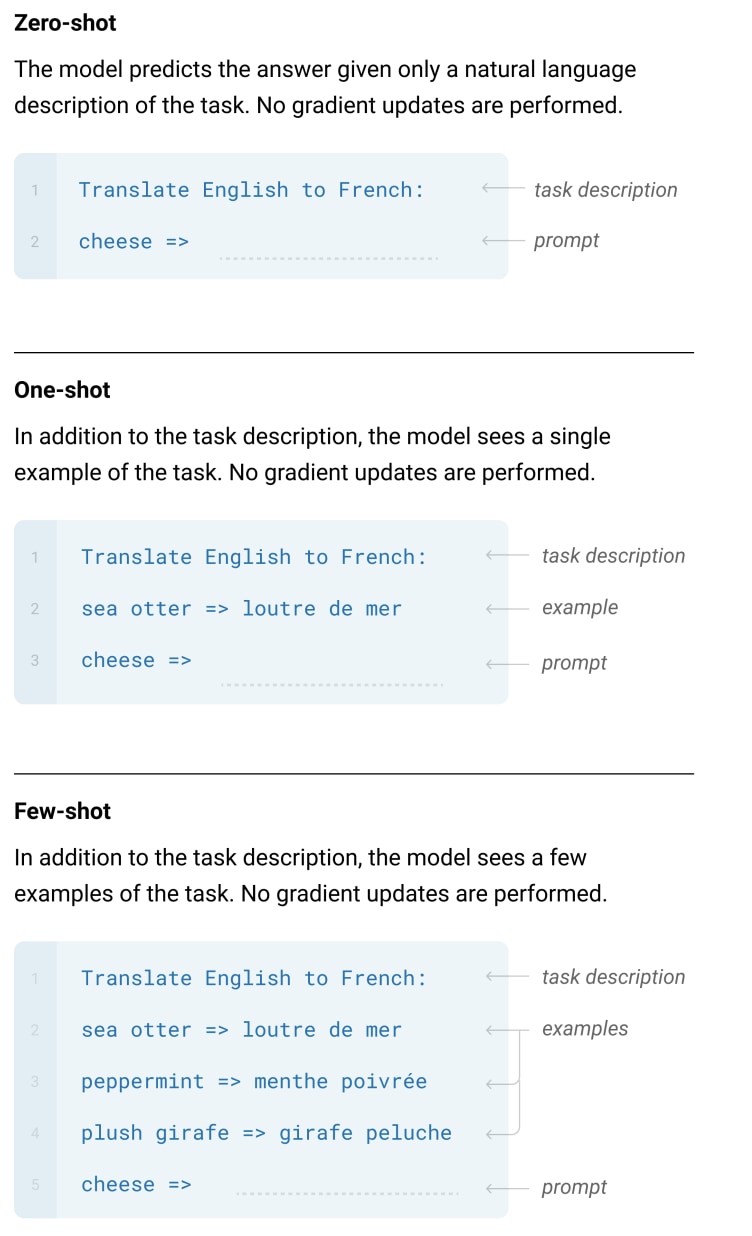
| ▼Description of terms in the figure “Task description” is the description of the task, “Translate English to French” for translation, “Please unscramble the letters into a word, and write that word:” for anagrams, etc. add to Example is an example of task input and correct answer output, in a form specific to each task. For example, for translation, “<input example> => <expression you want to use with the model>”, and for dialogue, “Human: <input example> AI: <expression you want to use with the model>”. A prompt takes the form of an input followed by the model’s answer. “<example input> =>” for translation. |
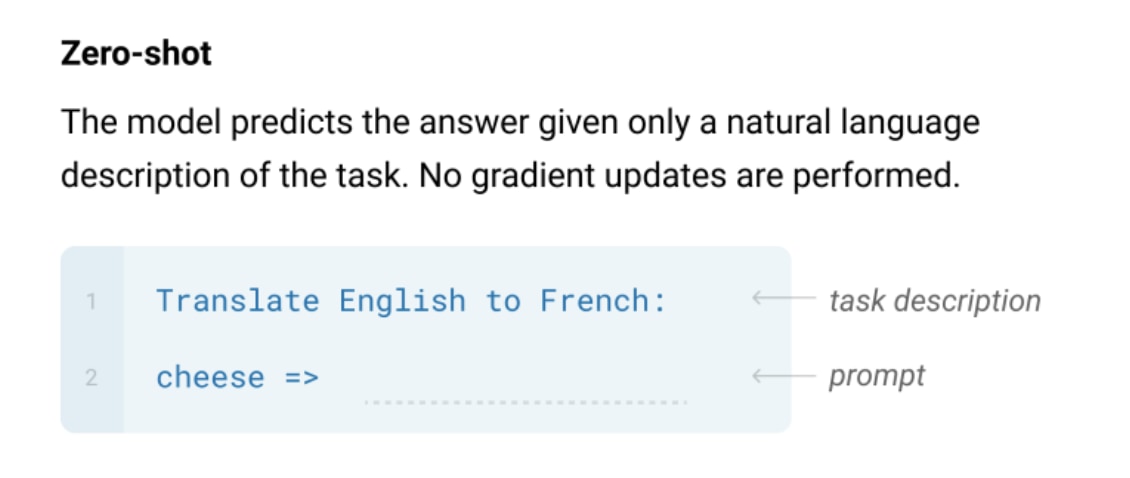
Zero-shot
Zero-shot is a format in which only the task description is given and no answer example is entered.
It’s a rather challenging task setup, without giving a single example. It is said that it is a task setting that is likely to be mistaken even by humans, and it is a difficult task. However, it is also mentioned that it is highly versatile and has the effect of avoiding the use of pseudo-correlation.
One-shot
One-shot is a format that gives only one Task description and example.

Easier than Zero-shot, but still a difficult task. It is explained that the reason for separating it from other tasks is that this format is the closest to how humans create data.
Few-shot
Few-shot is a format that gives 10 to 100 task descriptions and examples.

The simplest format. The number of examples you enter depends on how many examples fit into the input token limit (2048).
A noteworthy point of these is that fine tuning is not performed (= parameter updating is not performed) during task execution.
In other words, a single language model can solve different tasks (translation, dialogue, question answering, anagrams, etc.). It is said that this is similar to the state of human knowledge, and it is being verified one after another.
GPT-3 performance experiment
Finally, I will briefly touch on performance experiments of GPT-3.
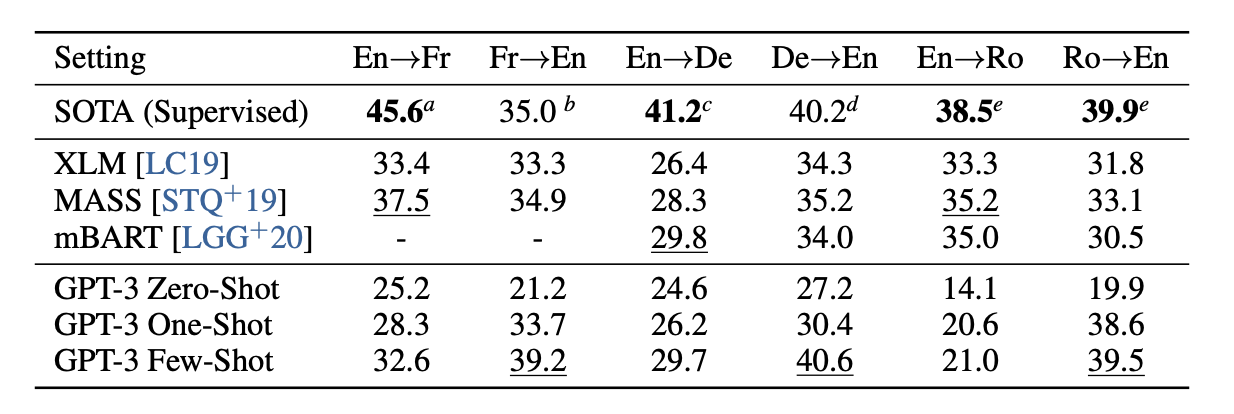
The table above summarizes the best performance and the performance of GPT-3.
The SOTA line is the best performance score, and the GPT-3 * below is the performance of GPT-3. It can also be observed that the accuracy increases remarkably if an example is given.
Other datasets often approach, but fall short of, the best performance, so it is surprising that a single model can achieve such accuracy.
in conclusion
This time, we have explained about GPT-3.
For those of you who have vaguely understood GPT-3 until now, I think that knowing these two features will deepen your understanding.