

Many people who are studying machine learning for the first time may think that “regression in machine learning seems difficult and I don’t really understand it.”
While regression in machine learning is a representative analysis method of machine learning, some people may find it a little difficult to approach due to its high degree of difficulty.
Therefore, this time, I will explain in detail the outline, advantages and disadvantages of “regression in machine learning” for beginners and intermediate users of machine learning.
In the second half of the article, we also introduce content where you can learn regression in machine learning, so please read it to the end.
Table of contents
- What is Regression in Machine Learning
- What is regression
- Difference Between Regression and Classification
- What is supervised learning
- Two types of typical machine learning regression
- linear regression
- decision tree
- What is Simple Regression and Multiple Regression in Machine Learning?
- simple regression
- multiple regression
- Benefits of Regression
- Statistically grounded predictions can be made
- Prediction is possible even where data does not exist
- Data can be displayed graphically
- Disadvantages of Regression
- A representative library in Python that can use regression
- How to learn machine learning regression
- Learn on learning site
- Learn from books
- Learn at school
- In conclusion
What is Regression in Machine Learning
What is regression
Regression in machine learning is “predicting one number from another using continuous values”.
For example, predicting tomorrow’s temperature from past temperatures or predicting sales in a company are examples of regression.
A feature of regression is that it can predict even where there is no data. This makes it possible to predict future figures from past data.
Difference Between Regression and Classification
In a nutshell, the difference between regression and classification is “do you use continuous values to predict another number, or do you use non-continuous or discrete values to distribute?”
Regression is a learning method that deals with quantities such as sales and rainfall probability, while classification is a learning method that determines the category, class, and type to which the data you want to analyze belongs, such as “determining whether the image is a dog or cat.” It is a method of judgment.
For now, it’s a good idea to remember that “regression is for predicting numerical values, and classification is for sorting.”
In this way, regression and classification differ in the process of analysis method, but both are based on supervised learning.
What is supervised learning?
As mentioned earlier, regression and classification belong to the group of supervised learning in machine learning.
What is this supervised learning? There are basically three groups in machine learning.
- supervised learning
- unsupervised learning
- reinforcement learning
Among these, supervised learning is a “method of learning with the correct answer given to the learning data”. This learning process is called “supervised” learning because it can be modeled on the teacher-student relationship.
On the other hand, unsupervised learning is a method of “learning without giving the correct answer to the learning data”, and reinforcement learning is a method of “improving while learning the strategy that the machine takes”.
Each learning method is explained in detail in another article, so if you are interested, please read it.
Two types of typical machine learning regression
There are two types of machine learning regression algorithms:
Linear regression
Linear regression is the straight line that, when data are distributed on a graph, that best approximates the spread of the distributed data. In machine learning, AI learns and finds a straight line. This straight line is called a regression line.
Decision tree
A decision tree is an algorithm that performs regression using a tree structure. Decision trees can do both classification and regression. Decision trees that use regression are called “regression trees” and can be used to predict numerical values.
In the case of a decision tree using regression, it divides into two in order, such as above or below a certain numerical value. The data is divided into a tree structure, but since continuous numerical values are predicted, it is “regression” rather than classification.
Decision trees can be used for classification, clustering, etc., in addition to regression. There is also a random forest in the derivation of decision trees.
What is Simple Regression and Multiple Regression in Machine Learning?
There are two types of regression: simple regression and multiple regression. Its features are as follows.
Simple regression
Simple regression predicts one target variable from one explanatory variable and can be expressed as “Y = AX + B”. It is common to determine this straight line from a scatterplot.
Examples include temperature data and sales of hot drinks.
The example predicts sales data for hot drinks using temperature data as an explanatory variable. The hot drink sales data at this time is called the objective variable.
Multiple regression
Multiple regression predicts one target variable from multiple explanatory variables.
For example, to derive the objective variable of the number of tourists in a tourist spot, we can use multiple explanatory variables such as the number of visitors to the website of the tourist spot, prices in the area, and the number of tourist facilities and sights. The formula is Y=A₁X₁+A₂X₂+A₃X₃+・・・+A₀.
Multiple regression is basically three or more dimensional in most cases, and is difficult to represent on a graph.
Benefits of Regression
The benefits of regression are:
Statistically grounded predictions can be made
Regression is an analytical technique that uses numbers, so predictions with statistical grounds are possible.
For example, when predicting the temperature, it is possible to explain that the temperature will be the same tomorrow because there is such data in the past, rather than that the prediction came about somehow. sex comes out.
Prediction is possible even where data does not exist
For example, in simple regression, it is possible to predict even the point where data does not exist because it fits the data in a linear formula.
For example, use this week’s data to predict the probability of rain next week.
Data can be displayed graphically
As mentioned in the previous simple regression example, regression fits data into a formula to make predictions. You can also visually see what kind of change this will make.
In simple regression, for example, the data are represented in a scatterplot. Derive the straight line that is closest to it. If you visually see the slope of the straight line, you can grasp what kind of change will occur.
Disadvantages of Regression
The disadvantage of regression is that “because it uses numerical values, it cannot be predicted unless it can be read and handled”.
As an advantage of regression, I explained that simple regression can be represented graphically.
However, since multiple regression results in a multi-dimensional graph, most of the cases cannot be expressed graphically. Therefore, it is imperative to read the data and work with it.
Therefore, it is a good idea to study mathematics knowledge such as statistics and linear algebra when doing regression.
A representative library in Python that can use regression
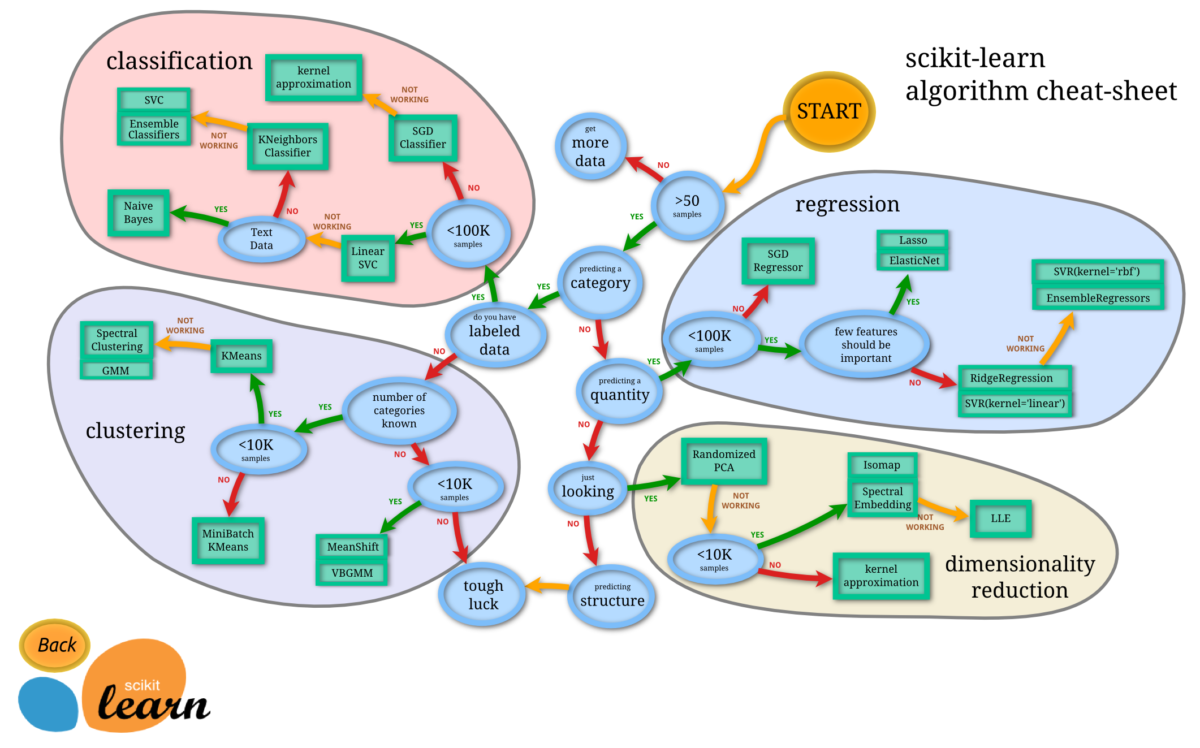
Scikit-learn is a typical Python library for machine learning.
scikit-learn comes with sample data already, so even beginners can start learning machine learning right away.
Also, scikit-learn has an algorithm cheat sheet. By using this sheet, it is possible to derive the optimal algorithm simply by answering the questions.
How to learn machine learning regression
learn on learning site
The first is “learning on the learning site”.
Learn about machine learning step-by-step with our learning site. In addition, it is characterized by a wide range of options from free to paid.
AI Academy is a recommended learning site . AI Academy allows you to learn while actually creating AI, so you can efficiently learn what you do not understand.
Another option is Udemy . Udemy has quality content, and with so much content, you’re bound to find something that works for you.
Learn from books
The second is “learning from books”.
The advantage of learning from books is that you can learn detailed information written by experts and you can write notes.
Books are written by experts and information is checked by the editorial department. Therefore, it has the advantage of being highly reliable.
Also, in the case of paper books, you can write notes, so you can check later where you did not understand. The advantage of e-books is that they are easy to carry around.
Here is a recommended book: “Illustrated ready-to-use textbook that clearly understands the mechanisms and techniques of machine learning and deep learning”
Learn at school
The third is to learn at school. To learn at school, there are things like learning online and learning face-to-face.
At an online school, you can learn when you like with video distribution. There are also educational institutions such as universities and vocational schools for face-to-face schools.
Both online and offline schools have the advantage of being able to ask questions directly to engineers and experts.
The recommended online school is ” AI Job Kare “. This online school allows you to systematically learn about AI.
Good for beginners and those who want to learn more.
In conclusion
In this article, we discussed regression in machine learning. How was that?
Try to see the difference between regression and classification, supervised learning groups. This field is also related to deep learning, so if you are a beginner, please try to understand it.

{kind=link}